-
SQL 은 기본적으로 구조적, 집합적, 선언적 질의 언어이다.
원하는 결과 집합을 구조적, 집합적으로 선언하지만, 그 결과 집합을 만드는 과정은 절차적일 수밖에 없다.
즉 프로시져가 필요한데, 그런 프로시져를 만들어 내는 DBMS 내부 엔젠이 바로 SQL 옵티마이저다.
옵티마이저가 프로그래밍을 대신해 주는 셈이다.
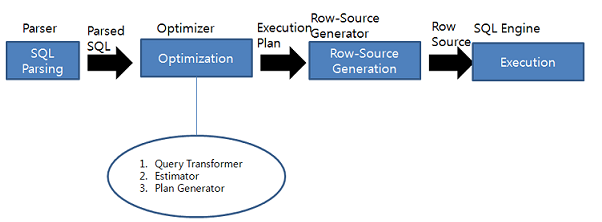
엔진 역할 Parser SQL 문장을 이루는 개별 구성요소를 분석하고 파싱해서 파싱 트리를 만든다.
이 과정에서 SQL 문법 오류(Syntax) , 의미상 오류(Sementic) 체크를 한다.Optimizer Query Transformer 파싱된 SQL 을 좀 더 일반적이고 표준적인 형태로 변환한다. Estimator 오브젝트 및 시스템 통계정보를 이용해 쿼리 수행 각 단계의 선택도,카디널리티,
비용을 계산하고, 궁극적으로는 실행계획 전체에 대한 총 비용을 계산해 낸다.Plan Generator 하나의 쿼리를 수행할 때, 후보군이 될만한 실행계획들을 생성해 낸다. Row-Source Generator 옵티마이저가 생성한 실행계획을 SQL 엔진이 실제 실행할 수 있는 코드(또는 프로시저) 형태로 포맷팅한다. SQL Engine SQL 을 실행한다. SQL 옵티마이저
사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 엑세스 경로를 선택해주는 DBMS 의 핵심 엔진이다.
옵티마이저의 최적화 단계를 요약하면 다음과 같다.
1. 사용자로부터 전달받은 쿼리를 수행하는 데 후보군이 될만한 실행계획들을 찾아낸다.
2. 데이터 딕셔너리에 미리 수집해둔 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
3. 최저 비용을 나타내는 실행계획을 선택한다.
옵티마이저 힌트
통계정보가 정확하지 않거나 기타 다른 이유로 옵티마이저가 잘못된 판단을 할 수 있다.
그럴 때 개발자가 직접 인덱스를 지정하거나 조인 방식을 변경함으로써 더 좋은 실행계획을 유도하는 매커니즘이 필요한데, 옵티마이저 힌트가 바로 그것이다.
힌트 종류와 구체적인 사용법은 DBMS 마다 천차만별이다.
Oracle 의 힌트
SELECT /*+ LEADING(e2 e1) USE_NL(e1) INDEX(e1 emp_emp_id_pk) USE_MERGE(j) FULL(j) */ el.first_name, e1.last_name, j.job_id, sum(e2.salary) total_sal FROM employees e1, employees e2, job_history j WHERE e1.employee_id = e2.manager_id AND e1.employee_id = j.employee_id AND e1.hire_date = j.start_date GROUP BY e1.first_name, e1.last_name, j.job_id ORDER BY total_sal;힌트가 무시되는 경우
- 문법적으로 틀리게 기술
- 의미적으로 틀리게 기술
- 잘못된 참조 사용 : 없는 Alias 나 인덱스명 사용
- 논리적으로 불가능한 엑세스 경로 : 조인절에 등치 조건이 없는데 해시 인으로 유도 / null 허용 컬럼에 인덱스로 건수 count
- 버그 : Oracle 은 힌트가 잘못되어도 에러를 발생시키지 않고 무시되기 때문에, 무언가 잘못 됐을 경우 성능에 대한 이슈는 사용자의 불평을 통해서 알게 된다.
DBMS 에 따라 이런 차이가 있기 때문에 애플리케이션 특성에 맞게 개발 표준과 DB 관리 정책을 수립할 필요가 있다.
힌트의 종류
분류 힌트 최적화 목표 all_rows
first_rows(n)액세스 경로 full
cluster
hash
index, no_index
index_asc , index_desc
index_combine
index_join
index_ffs, no_index_ffs
index_ss, no_index_ss
indesc_ss_asc, indesc_ss_desc쿼리 변환 no_query_transformation
use_concat
no_expand
rewrite , no_rewrite
merge, no_merge
star_transformation, no_star_transformation
fact, no_fact
unnest, no_unnest조인 순서 ordered
leading조인 방식 use_nl, no_use_nl
use_nl_with_index
use_merge, no_use_merge
use_hash, no_use_hash병렬 처리 parallel, no_parallel
pq_distribute
parallel_index, no_parallel_index기타 append, noappend
cache, nocache
push_pred, no_push_pred
push_subq , no_push_subq
qb_name
cursor_sharing_exact
driving_site
dynamic_sampling
model_min_analysis데이터베이스 I/O 매커니즘
1. 블록단위 I/O
Oracle 을 포함한 모든 DBMS 에서 I/O 는 블록 단위로 이뤄진다. 즉 하나의 레코드를 읽더라도 레코드가 속한 블록 전체를 읽는다. SQL 성능을 좌우하는 가장 중요한 성능 지표는 엑세스하는 블록 개수이며, 옵티마이저의 판단에 가장 큰 영향을 미치는 것도 엑세스해야 할 블록 개수이다.
블록단위 I/O 는 버퍼캐시와 데이터 파일 I/O 모두에 적용된다.
- 데이터 파일에서 DB 버퍼 캐시로 블록을 적재할 때
- 데이터 파일에서 블록을 직접 읽고 쓸 때
- 버퍼 캐시에서 블록을 읽고 쓸 때
- 버퍼 캐시에서 변경된 블록을 다시 데이터 파일에 쓸 때
2. 메모리 I/O vs. 디스크 I/O
가. I/O 효율화 튜닝의 중요성
디스크를 경유한 데이터 입출력은 디스크의 액세스 암(Arm) 이 움직이면서 헤드를 통해 데이터를 읽고 쓰기 때문에 느린 반면, 메모리를 통한 입출력은 전기적 신호에 불과하기 때문에 훨씬 빠르다.
모든 DBMS 는 읽고자 하는 블록을 먼저 버퍼 캐시에서 찾아보고 없을 때만 디스크에서 읽어 버퍼 캐시에 적재한다.
물리적인 디스크 I/O 가 필요할 때면 서버 프로세스는 시스템에 I/O Call 을 하고 잠시 대기 상태에 빠진다. 디스크 I/O 경합이 심할수록 대기 시간도 길어진다.
메모리는 물리적으로 한정된 자원이므로, 결국 디스크 I/O 를 최소화하고 버퍼 캐시 효율을 높이는 것이 데이터베이스 I/O 튜닝의 목표가 된다.
나. 버퍼 캐시 히트율 (BCHR)
버퍼 캐시 효율을 측정하는 지표로서, 전체 읽은 블록 중 메모리 버퍼 캐시에서 찾은 비율을 나타낸다.
즉 버퍼 캐시 히트율은 물리적인 디스크 읽기를 수반하지 않고 곧바로 메모리에서 블록을 찾은 비율을 말한다.
Direct Path Read 방식 이외의 모든 블록 읽기는 버퍼 캐시를 통해 이뤄진다.
BCHR = (버퍼 캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수) x 100
BCHR 은 주로 시스템 전체적인 관점에서 측정하지만, 개별 SQL 측면에서 구해볼 수도 있는데 이 비율이 낮은 것이 SQL 성능을 떨어뜨리는 주원인이라고 할 수 있다.
아래 disk 항목이 디스크를 경유한 블록 수를 의미하며, query와 current 항목이 버퍼 캐시에서 읽은 블록 수를 말한다.
총 88개 블록을 읽었는데, 물리적 블록을 읽은 수 (disk) 는 0 , 논리적 블록을 읽은 수 (query+current) 이다.

논리적인 블록 요청 횟수를 줄이고, 물리적으로 디스크에서 읽어야 할 블록 수를 줄이는 것이 I/O 효율화 튜닝의 핵심 원리이다.
- SQL을 수행하는 동안 캐시에서 읽은 총 블록 수를 '논리적 블록읽기(Logical Reads)'
- 그리고 '캐시에서 곧바로 찾은 블록 수'는 디스크를 경유하지 않고 버퍼 캐시에서 찾은 블록 수를 말하므로 '총 읽은 블록 수(=논리적 블록읽기)'에서 '물리적 블록읽기(Physical Reads)'를 차감해서 구한다.
- 물리적 블록읽기 : Disk 항목
- 논리적 블록읽기 : Query + Current 항목
같은 블록을 반복적으로 액세스하는 형태의 SQL 은 논리적인 I/O 요청이 비효율적으로 많이 발생함에도 불구하고 BCHR 은 매우 높게 나타난다. 이는 BCHR 이 성능지표로서 갖는 한계점이라 할 수 있다.
예를 들어 NL 조인에서 작은 Inner 테이블을 반복적이로 lookup 하는 경우가 그렇다.
작은 테이블을 반복 액세스하면 모든 블록이 메모리에서 찾아져 BCHR 은 높겠지만 일량이 작지 않고, 블록을 찾는 과정에서 래치*경합과 버퍼 Lock 경합까지 발생한다면 메모리 I/O 비용이 디스크 I/O 비용보다 커질 수 있다.
따라서 논리적으로 읽어야 할 블록 수의 절대량이 많다면 반드시 튜닝을 통해 논리적인 블록 읽기를 최소화해야 한다.
* 래치 : LRU 에서 사용자가 실행한 SQL문에 의해 테이블 데이터가 데이터버퍼 캐시 영역에 저장되기 위해서는 LRU LIST로부터 FREE BUFFER를 찾아야하는데, 만약 서버 프로세스가 하나의 FREE BUFFER를 찾았다면 이것을 "래치를 얻었다"라고 합니다. 하나의 서버 프로세스가 얻은 하나의 래치는 약 50개의 FREE BUFFER를 동시에 처리할 수 있습니다. 하나의 서버 프로세스는 지금 이 순간에도 하나의 래치를 얻기 위해 다른 서버 프로세스와 경합을 벌여 FREE BUFFER를 찾게 됩니다. 오라클 데이터베이스를 설치하면 LRU 래치의 기본 값은 1입니다. 사용자 수가 많은 데이터베이스 환경이라면 래치를 얻기 위한 경합(CONTENTION)으로 인해 성능이 저하될 수도 있습니다. 래치의 경합현상은 V$LATCH 자료사전을 통해 알 수 있는데 GETS 컬럼은 LATCH를 얻은 수이며 SLEEPS 컬럼은 LATCH를 얻지 못하고 대기(WAITING)했던 수를 의미합니다. GETS 컬럼에 대해 SLEEPS 컬럼이 99% 이상의 백분율을 보일 때 경합이 발생하지 않기 때문에 좋은 성능을 기대할 수 있습니다. 출처: https://redkite777.tistory.com/entry/오라클1-5단계-래치와-경합 [All Days 무한도전]다. 네트워크, 파일시스템 캐시가 I/O 효율에 미치는 영향
대용량 데이터를 읽고 쓰는데 다양한 네트워크 기술이 사용됨에 따라 네트워크 속도도 SQL 성능에 영향을 미친다.
네트워크 전송량이 많을수록 좋은 성능을 기대할 수 없으니 SQL 을 작성할 때는 다양한 I/O 튜닝 기법을 사용해 네트워크 전송량을 줄이려고 노력해야한다.
RAC*같은 클러스터링 데이터베이스 환경에선 인스턴스 간 캐시된 블록을 공유하므로 메모리 I/O 성능에도 네트워크 속도가 지대한 영향을 미치게 되었다.
같은 양의 디스크 I/O 가 발생하더라도 대기 시간이 크게 차이날 때가 있다. 디스크 경합 때문일 수도 있고, OS 에서 지원하는 파일 시스템 버퍼 캐시와 SAN 캐시 때문일 수도 있다. SAN 캐시는 커도 문제가 되지 않지만, 파일시스템 버퍼캐시는 최소화해야한다.
* RAC(Real Application Cluster) : DB서버의 장애를 대비해서 DB서버를 2대 이상 설치하는 것. 2대의 DB 서버의 내용은 반드시 같아야한다.
3. Sequential I/O vs. Random I/O
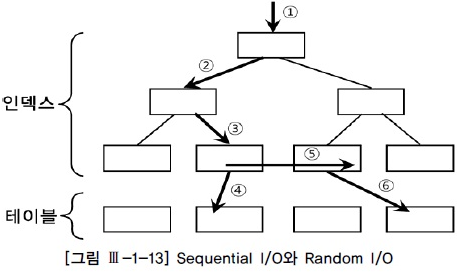
시퀀스 엑세스는 레코드간 논리적 또는 물리적인 순서를 따라 차례대로 읽어 나가는 방식이다.
인덱스 리프 블록에 위치한 모든 레코드는 포인터를 따라 논리적으로 연결돼 있고, 이 포인터를 따라 스캔하는 것(위 그림에서 ⑤)은 시퀀셜 엑세스 방식이다. 테이블 레코드 간에는 포인터로 연결되지 않지만 테이블을 스캔할 때는 물리적으로 저장된 순서대로 읽어 나가므로 이것 또한 시퀀셜 액세스 방식이다.
랜덤 액세스는 레코드간 논리적, 물리적 순서를 따르지 않고 , 한 건을 읽기 위해 한 블록씩 접근하는 방식(④, ⑥)을 말한다.
블록 단위 I/O 를 하더라도 한번 액세스 할 때 시퀀셜 방식으로 그 안에 저장된 모든 레코드를 읽는다면 비효율은 없다. 반면, 하나의 레코드를 읽으려고 한 블록씩 랜덤 액세스한다면 매우 비효율적이라고 할 수 있다.
여기서 I/O 튜닝의 핵심 원리 두 가지를 발견할 수 있다. 1. 시퀀셜 엑세스 비중을 높인다. 2. 랜덤 액세스 발생을 줄인다.
- 시퀀셜 액세스에 의한 선택 비중 높이기
시퀀셜 액세스 효율성을 높이려면, 읽은 총 건수 중에서 결과 집합으로 선택되는 비중을 높여야 한다.
즉 같은 결과를 얻기 위해 얼마나 적은 레코드를 읽느냐로 효율성을 판단할 수 있다.
* CR(Consistent Read) Consistent Read Mode* 로 특정 블록을 Buffer Cache에서 읽는 것을 의미
* CU(Current Read) 특정 블록을 변경할 목적으로 Current Mode*로 Buffer Cache에서 읽는 것을 의미
* PR(Physical Read) 특정 블록을 Disk에서 읽어 Buffer Cache에 적재하는 것을 의미아래 쿼리문을 실행하면서 SQL Trace 를 확인하면 cr 숫자 (읽은 블록 수) 를 확인할 수 있다.
인덱스를 생성해 사용할 때 인덱스 구성에 따라서도 효율성이 결정되는 것을 확인할 수 있다.조건절에 사용된 컬럼, 연산자의 형태, 인덱스의 구성에 따라 효율성이 결정된다.
-- 49906 SELECT COUNT(*) FROM T; -- ROWS 24613 , cr=691 SELECT COUNT(*) FROM T WHERE OWNER LIKE 'SYS%'; -- ROWS 1 , cr=691 SELECT COUNT(*) FROM T WHERE OWNER LIKE 'SYS%' AND OBJECT_NAME='ALL_OBJECTS'; CREATE INDEX t_idx ON T(OWNER, OBJECT_NAME); -- ROWS 1 , cr=76 SELECT /*+ index(T t_idx) */ COUNT(*) FROM T WHERE OWNER LIKE 'SYS%' AND OBJECT_NAME='ALL_OBJECTS'; CREATE INDEX t_idx2 ON T(OBJECT_NAME,OWNER); -- ROWS 1 , cr=2 SELECT /*+ index(T t_idx2) */ COUNT(*) FROM T WHERE OWNER LIKE 'SYS%' AND OBJECT_NAME='ALL_OBJECTS';4. Single Block I/O vs. MultiBlock I/O
Single Block I/O 는 한 번의 I/O Call 에 하나의 데이터 블록만 읽어 메모리에 적재하는 방식이다. 인덱스를 통해 테이블을 액세스할 때는, 기본적으로 인덱스와 테이블 블록 모두 이 방식을 사용한다.
MultiBlock I/O 는 I/O Call 이 필요한 시점에, 인접한 블록들을 같이 읽어 메모리에 적재하는 방식이다.
Table Full scan처럼 물리적으로 저장된 순서에 따라 읽을 때는 인접한 블록들을 같이 읽는 것이 유리하다.
'인접한 블록' 이란, 한 익스텐트내에 속한 블록을 말한다. 달리 말하면 MultiBlock I/O 방식으로 읽더라도 익스텐트 범위를 넘어서까지 읽지는 않는다.
인덱스 스캔 시에는 Single Block I/O 방식이 효율적이다. 인덱스 블록 간 논리적 순서는 데이터 파일에 저장된 물리적인 순서와 다르기 때문이다. 물리적으로 한 익스텐트에 속한 블록들을 I/O Call 시점에 메모리에 올렸는데, 그 블록들이 논리적인 순서로는 한참 뒤쪽에 위치할 수 있다. 그러면 그 블록들은 실제로 사용되지 못하고 버퍼 상에서 밀려나는 일이 발생한다. 하나의 블록을 캐싱하려면 다른 블록을 밀어내야하는데, 이런 현상이 자주 발생하면 버퍼 캐시 효율을 떨어뜨린다.
오라클 10g 부터는 Index Range Scan 또는 Index Full Scan 일 도 MultiBlock 방식으로 읽는 경우가 있다. 테이블 엑세스 없이 인덱스만 읽고 처리할 때가 그렇다. 인덱스를 스캔하면서 테이블을 랜덤 액세스랑 때는 9i 버전과 동일하게 테이블과 인덱스 블록을 모두 Single Block 방식으로 읽는다.
** 문장수준 읽기 일관성 **
Consistent 모드 : 쿼리 실행 시간에 상관없이 항상 쿼리가 시작된 시점의 데이터를 가져옴
① CR copy 생성 없이 Current 블록*을 읽어도 집계에 포함
② SELECT 문에서 읽은 대부분의 블록
③ CR 블록*을 생성하려고 읽어들인 Undo 세그먼트 블록도 집계에 포함** Current, CR 블록
- Current 블록은 디스크로부터 읽혀진 후 사용자의 갱신사항이 반영된 최종 상태의 원본 블록을 말하며,
- CR 블록은 Current 블록에 대한 복사본이다.
- CR 블록은 여러 버전이 존재할 수 있지만 Current 블록은 한개 뿐이다.Consistent 모드에서 생길 수 있는 문제
① TX2는 TX1에 걸린 Lock 대기 (Row Lock)
② t2 시점에 SAL은 1000이었므로 TX1이 commit된 후 1,000을 가지고 UDPATE (Read Committed라고 가정)
③ 최종값은 1200이 되고 TX1의 처리 결과는 사라짐, Lost Update 발생- Lost Update 문제를 회피하려면 갱신 작업만큼은 Current모드를 사용해야 한다.
- TX2 update는 Exclusive Lock 때문에 대기했다가 TX1 트랜잭션이 커밋한 후 Current 모드로 그 값을 읽어 진행을 계속한다.
----------------------------------------------------------------------------------------
TX1 select price (1000) TX2 select price (1000)
----------------------------------------------------------------------------------------
TX1 update 1000+100 = 1100;COMMIT;
----------------------------------------------------------------------------------------
TX2 update 1000+200= 1200;COMMIT;
----------------------------------------------------------------------------------------
-Current 모드 읽기 : 쿼리가 시작된 시점이 아닌 데이터를 찾아간 그 시점의 최종 값을 가져옴
① DML문 수행 시
② SELECT FOR UPDATE문 수행 시
③ disk sort가 필요할 정도의 대량 데이터를 정렬 시
- Current 모드에서 생길 수 있는 문제----------------------------------------------------------------------------------------
TX1 update emp set sal = 2000 where empno = 7788 and sal = 1000
----------------------------------------------------------------------------------------
TX2 update emp set sal = 3000 where empno = 7788 and sal = 2000;
----------------------------------------------------------------------------------------
TX1 COMMIT;
----------------------------------------------------------------------------------------
TX2 COMMIT;
----------------------------------------------------------------------------------------
- 항상 Current 모드로만 작동하는 Sybase, SQL Server 같은 DBMNS에서 수행해 보면 실제 위와 같은 결과(3,000)가 나온다.
- 오라클에서는 TX2의 갱신이 실패하므로 최종 값은 2,000이 된다.
② Full Table Scan 방식으로 UPDATE 진행하는 경우
→ 레코드가 INSERT 되는 위치에 따라 UPDATE 결과 건수가 달라짐(이미 지나간 블록에 삽입된다면 50,000 건 UPDATE, 앞으로 지나갈 블록에 삽입된다면 50,001 건 UPDATE)
※ UPDATE나 DELETE 에 대해서도 위와 같은 현상이 일어날 수 있다.----------------------------------------------------------------------------------------
TX1 update t set no = no + 1 where no > 50000;
----------------------------------------------------------------------------------------
TX2 insert into t values(100001, 100001); COMMIT;
----------------------------------------------------------------------------------------
TX1 COMMIT;
----------------------------------------------------------------------------------------
- TX1이 1~100,000까지의 Unique한 번호를 가진 테이블에서 no>50000 조건에 해당하는 50,000개 레코드에 대해 인덱스를 경유해 순차적으로 갱신 작업을
진행하고 있다고 하자. 그런데 도중에 TX2 트랜젝션에서 no값이 100,001인 레코드를 새로 추가하면 update 되는 최종 결과건수는? => 50,001건(MSSQL) - 인덱스 경우가 아닌 Full Table Scan 방식으로 진행되었다면 insert되는 위치에 따라 결과 건수가 달라진다.
- 다른예로 "delete from 로그" 문장이 수행되는 도중에 다른 트랜잭션에 의해 새로 추가된 로그 데이터까지 지워질 수도 있다.
- 오라클에서는 TX2가 레코드를 insert하는 위치에 상관없이 TX1은 항상 50,000건만 갱신된다.
Consistent 모드로 갱신대상을 식별하고, Current 모드로 갱신
- 실제 오라클이 UPDATE를 처리하는 방식
http://wiki.gurubee.net/pages/viewpage.action?pageId=3900220
https://jungmina.com/786
출처
SQL 전문가 가이드 - 한국데이터산업진흥원
반응형'데이터베이스' 카테고리의 다른 글
SQLD 문제 다시 보기 (0) 2021.05.26 SQL 분석 도구 (0) 2021.05.24 데이터베이스 아키텍처 (0) 2021.05.20 유저와 권한 (0) 2021.05.20 트랜젝션 (0) 2021.05.20