-
트랜젝션은 데이터베이스의 논리적 연산단위이다.
트랜젝션이란 밀접히 관련돼 분리될 수 없는 한 개 이상의 데이터베이스 조작을 가리킨다.
하나의 트랜젝션에는 하나 이상의 SQL 문장이 포함된다.
트랜젝션은 분할할 수 없는 최소의 단위이다. 그러므로 전부 적용하거나 전부 취소한다. ALL OR NOTING 의 개념이다.
계좌이체 같은 하나의 논리적인 작업 단위를 구성하는 세부적인 연산들의 집합을 트랜젝션이라 한다.
(100번 계좌에서 5천원을 뺀다. + 200번계좌 잔액에 5천원을 더한다.)
이런 관점에서 데이터베이스 응용 프로그램은 트랜젝션의 집합으로 정의할 수도 있다.
트랜젝션을 제어하는 명령문 - TCL
COMMIT, ROLLBACK, SAVEPOINT 명령어가 있다.
트랜젝션의 대상
대상이 되는 SQL 문은 INSERT,UPDATE, DELETE 등의 DML 문이다.
SELECT 는 직접적인 트랜젝션 대상이 아니지만, SELECT FOR UPDATE 등 배타적 LOCK 을 요구하는 SELECT 문장은 트랜젝션의 대상이 될 수 있다.
트랜젝션의 특성
원자성(atomicity) 트랜젝션 내 연산들이 모두 성공적으로 실행되던가 아니면 전혀 실행되지 않은 상태여야한다.
all or nothing일관성(consistency) 트랜젝션 실행되지 전의 데이터베이스 내용이 잘못 되어있지 않으면,
실행 후에도 잘못된 내용이 없어야한다.고립성(isolation) 트랜젝션이 실행되는 도중에 다른 트랜젝션의 영향을 받아 잘못된 결과를 만들어서는 안된다. 지속성(durability) 트랜젝션이 성공적으로 수행되면, 그 트랜젝션이 갱신한 데이터베이스의 내용을 영구적으로 저장된다. 트랜젝션의 특성(특히 원자성) 을 충족하기 위해서 데이터베이스는 다양한 레벨의 잠금 기능을 제공한다.
잠금을 기본적으로 트랜젝션이 수행되는 동안 다른 트랜젝션이 동시 접근하지 못하게 제한하는 기법이다.
잠금이 걸린 데이터는 잠금을 수행한 트랜젝션만 해제할 수 있다.
COMMIT : 입력, 수정, 삭제 데이터에 대해 문제가 없다고 판단되면, COMMIT 으로 트랜젝션을 완료할 수 있다.
ROLLBACK : 입력, 수정, 삭제 데이터에 대해 COMMIT 이전에는 변경사항을 ROLLBACK 으로 취소할 수 있다.
COMMIT 이나 ROLLBACK 이전의 데이터 상태
- 데이터 변경을 취소해 이전 상태로 복구 가능
- 현재 사용자는 SELECT 문으로 결과 확인 가능
- 다른 사용자는 현재 사용자가 수행한 명령의 결과를 보는 것이 불가능
- 변경된 행은 LOCKING 설정되어 다른 사용자의 변경이 불가능
COMMIT 이후의 데이터 상태
- 변경 사항이 데이터베이스에 반영
- 이전 데이터 영원히 분실
- 모든 사용자는 결과를 볼 수 있음
- 관련된 행에 LOCKING 이 풀리고, 다른 사용자들의 변경이 가능
ROLLBACK 이후의 데이터 상태
- 데이터의 변경 사항이 취소됨
- 데이터가 트랜젝션 시작 이전의 상태로 되돌아감
- 관련된 행에 LOCKING 이 풀리고, 다른 사용자들의 변경이 가능
COMMIT 이나 ROLLBACK 의 효과
- 데이터 무결성 보장
- 영구적 변경을 하기 전에 데이터 변경 사항 확인 가능
- 논리적으로 연관된 작업을 그루핑해 처리 가능
SQL 서버에서 트랜젝션의 세 가지 방식
1. AUTO COMMIT
SQL 의 기본 방식이며, DML과 DDL 을 수행할 때마다 DBMS 가 트랜젝션을 컨트롤하는 방식이다.
명령어가 성공적으로 수행되면 자동으로 COMMIT 을 수행하고, 오류가 발생하면 자동으로 ROLLBACK 을 수행한다.
2. 암시적 트랜젝션
Oracle 과 같은 방식으로 처리된다.
즉 트랜젝션의 시작은 DBMS 가 처리하고, 트랜젝션의 끝은 사용자가 명시적으로 COMMIT 아니 ROLLBACK 으로 처리한다.
인스턴스 단위 또는 세션 단위로 설정할 수 있다. 인스턴스 단위로 설정하려면 서버 속성 창의 연결화면에서 기본연결 옵션 중 암시적 트랜젝션에 체크해주면 된다. 세션 단위로 설정하기 위해서는 세션 옵션 중 SET IMPLICIT TRANSACTION ON 을 사용하면 된다.
3. 묵시적 트랜젝션
트랜젝션의 시작과 끝을 모두 사용하자 명시적으로 지정하는 방식이다.
BEGIN TRANSACTION (BEGIN TRAN) 으로 트랜젝션을 시작하고, COMMIT TRANSACTION(COMMIT) 으로 트랜젝션을 종료한다.
ROLLBACK 구문을 만나면 최초의 BEGIN TRANSACTION 시점까지 모두 ROLLBACK 이 수행된다.
SAVEPOINT
SAVEPOINT 를 정의하면 ROLLBACK 할 때 트랜젝션에 포함된 전체 작업을 ROLLBACK 하는 것이 아니라,
현 시점에서 SAVEPOINT 까지 트랜젝션의 일부만 롤백할 수 있다.
따라서 복잡한 대규모 트랜젝션에서 에러가 발생했을 때 SAVEPOINT 까지의 트랜젝션만 롤백하고 실패한 부분에 대해서만 다시 실행할 수 있다.
복수의 저장점을 정의할 수 있으며, 동일 이름으로 여러 개의 저장점을 정의하면 마지막에 정의한 저장점만 유효하다.
SAVEPOINT SV1; ROLLBACK TO SV1; SAVE TRANSACTION SVTR; ROLLBACK TRANSACTION SVTR;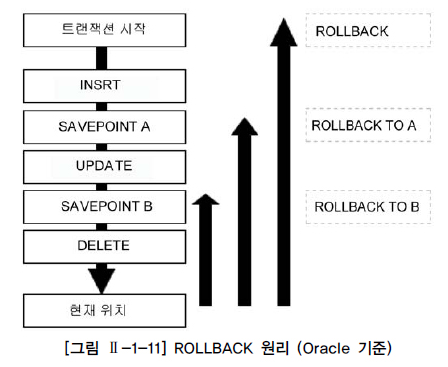
위 그림에서 ROLLBACK 을 A 까지 실행한 뒤, 다시 B로 갈 수 없다. A 지점에서는 B는 미래 방향이기 때문이다.
즉 ROLLBACK TO A 를 실행한 시점에서 저장점 B는 존재하지 않는다.
저장점 지정 없이 ROLLBACK 을 실행할 경우, 반영되지 않은 모든 변경 사항을 취소하고 트랜젝션을 종료한다.
Oracle 의 트랜젝션은 트랜젝션의 대상이 되는 SQL 문을 실행하면 자동으로 시작되고,
COMMIT 또는 ROLLBACK 을 실행한 시점에서 종료된다. 단 다음의 경우에는 COMMIT / ROLLBACK 을 실행하지 않아도 자동으로 트랜젝션이 종료된다.
- CREATE, ALTER, DROP, RENAME, TRUNCATE TABLE 등의 DDL 문장 실행
- 데이터베이스를 정상적으로 접속 종료 하면 자동으로 트랜젝션이 COMMIT 된다.
- 애플리케이션의 이상 종료로 데이터베이스와 접속이 단절되면 트랜젝션이 자동으로 ROLLBACK 된다.
트랜젝션 격리성
일관성과 마찬가지로 Lock 을 강하게 오래 유지할수록 강화되고 Lock 을 최소화할수록 약화된다.
낮은 단계의 격리성 수준에서 발생할 수 있는 현상들
1. Dirty Read
다른 트랜젝션이 수정한 후 커밋하지 않은 데이터를 읽는 것.
변경 후 아직 커밋되지 않은 값을 읽었는데, 변경을 가한 트랜젝션이 롤백된다면 그 값을 읽은 트랜젝션은 비일관된 상태에 놓이게 된다.
2. Non-Repeatable Read
한 트랜젝션 내에서 같은 쿼리를 두 번 수행했는데, 그 사이에 다른 트랜젝션이 값을 수정 또는 삭제하는 바람에 두 쿼리 결과가 다르게 나타나는 현상을 말한다.

3. Phantom Read
한 트랜젝션 내에서 같은 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 없던 유령(Phantom) 레코드가 두 번째 쿼리에서 나타나는 현상을 말한다.
트랜젝션 격리성 수준
- Read UnCommitted
트랜젝션에서 처리 중인 아직 커밋되지 않은 데이터를 다른 트랜젝션이 읽는 것을 허용한다.
- Read Commited
트랜젝션이 커밋된 확정 데이터만 읽도록 허용해 Dirty Read 를 방지한다.
커밋된 데이터만 읽더라도 Non Repeatable 과 Phantom Read 현상을 막지는 못한다. 읽는 시점에 따라 결과가 다를 수 있다는 것이다.
- Repeatable Read
트랜젝션 내에서 쿼리를 두 번 수행할 때, 첫 번째 쿼리에 있던 레코드가 사라지거나 값이 바뀌는 현상을 방지해준다.
이 트랜젝션 격리성 수준이 Phantom Read 를 막지는 못한다. 첫 번째 쿼리에서 없던 새로운 레코드가 나타날 수 있다.
- Serializable Read
트랜젝션 내에서 쿼리를 두 번 이상 수행할 때, 첫번째 레코드가 사라지거나 값이 바뀌지 않음은 물론 새로운 레코드가
나타나지도 않는다.
레벨 Dirty Read Non-Repeatable Read Phantom Read Read UnCommitted 가능 가능 가능 Read Commited 불가능 가능 가능 Repeatable Read 불가능 불가능 가능 Serializable Read 불가능 불가능 불가능 트랜젝션 격리성 수준은 ISO 에서 정한 분류 기준으로, 모든 DBMS 에서 지원하는 것은 아니다.
SQL Server 와 DB2 는 4가지 레벨을 모두 지원,
Oracle 은 Read Commited 와 Serializable Read 만 허용한다. (Repeatable Read 를 구현하려면 for update 구문 이용)
대부분의 DBMS 가 Read Commited 를 기본 트랜젝션 격리성 수준으로 지원해, Dirty Read 발생을 걱정하지 않아도 된다.
다중 트랜젝션 환경에서 DBMS 가 제공하는 기능을 이용해 동시성을 제어하려면 트랜젝션 시작 전에 명시적으로
Set Transaction 명령어를 수행하기만 하면 된다.
-- Serializable Read 수준으로 트랜젝션 격리성을 상향 조정 set transaction isolation level read serializable;트랜젝션 격리성 수준을 Repeatable 이나 Serializable 로 올리면 ISO 에서 정한 기준을 만족해야하며,
대부분 DBMS 가 이를 구현하기 위해 Locking 매커니즘에 의존한다.
좀 더 구체적으로 말하면, 공유 Lock 을 트랜젝션이 끝날 때까지 유지하는 방식을 사용한다.
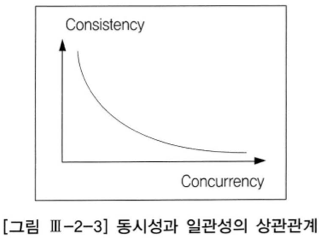
문제는 동시성이다.
한 건씩 읽어 처리할 때는 잘 느끼지 못하는 수준이지만, 대량의 데이터를 읽어 처리할 때는 동시성이 심각하게 낮아진다. 완벽한 데이터 일관성 유지를 위해 테이블 레벨 Lock 을 걸어야 할 때도 있다.
이에 대한 대안으로 다중버전 동시성 제어(Multiversion Concurrency Control)을 채택하는 DBMS 도 조금씩 늘고 있다.
'스냅샷 격리성 수준(Snapshot Isolation level)' 이라고 불리는 이 방식을 요약하면,현재 진행중인 트랜젝션에 의해 변경된 데이터를 읽고자 할 때는 변경 이전 상태로 되돌린 버전을 읽는 것이다.
변경이 아직 확정되지 않은 값을 읽으려는 것이 아니므로 공유 Lock 을 설정하지 않아도 된다. 따라서 읽는 세션과 변경하는 세션이 서로 간섭현상을 일으키지 않는다.
tx2 트랜젝션에 의해 새로운 고객이 등록되어도 tx1 트랜젝션은 그 값을 무시한다. 트랜젝션 내내 자신이 시작된 tx1 시점을 기준으로 읽기 때문에 데이터 일관성은 물론 높은 동시성을 유지할 수 있다.
동시성 제어 Concurrency Control
DBMS 는 다수의 사용자를 가정하기 때문에, 동시에 작동하는 다중 트랜젝션의 상호 간섭 작용레서 데이터베이스를 보호할 수 있어야한다. 이를 동시성 제어라고 한다.
동시성을 제어하기 위해 모든 DBMS 가 공통적으로 Lock 기능을 제공한다. 여러 사용자가 데이터를 동시에 엑세스 하는 것처럼 보이지만 내부적으로는 하나씩 실행되도록 트랜젝션을 직렬화하는 것이다.
기본 트랜젝션 격리성 수준인 Read Commited 상태에선 레코드를 읽고 다음 레코드로 이동하자마자 공유 Lock 을 해제하지만, Repeatable Read 로 올리면 트랜젝션을 커밋할 때까지 공유 Lock 을 유지한다.
동시성 제어가 어려운 이유가 여기 있는데, 동시성과 일관성은 트레이드 오프(trade-off) 관계이다.
동시성을 높이려고 Lock 사용을 최소화하면 일관성 유지가 어렵고, 일관성을 높이려고 Lock 을 적극 사용하면 동시성이 저하된다.
DMBS 가 제공하는 set transaction 명령어로 모든 동시성 제어 문제를 해결할 수 없다.
n-Tier 아키텍처가 지배적인 요즘 같은 애플리케이션 환경에서 특히 그렇다. 예를 들어 사용자가 자신의 계좌에서 잔고를 확인하고 인출을 완료할 때까지 논리적 작업 단위를 하나의 트랜젝션에서 처리하고자 할 때, 잔고를 확인하는 SQL 과 인출하는 SQL 이 서로 다른 연결 (Connection) 을 통해 처리될 수 있기 때문이다.
DB 와 연결하기 위해 라이브러리나 그리드(Grid) 컴포넌트가 동시성 제어 기능을 제공하기도 하지만, 많은 경우 트랜젝션의 동시성을 개발자가 직접 구현해야한다.
동시성 제어 기법에는 비관적 동시성 제어과 낙관적 동시성 제어라는 두가지가 있다.
비관적 동시성 제어 Pessimistic Concurrency Control
사용자들이 같은 데이터를 동시에 수정할 것이라고 가정하고, 데이터를 읽는 시점에 Lock 을 걸로 트랜젝션이 완료될 때까지 유지한다.
SELECT 적립포인트, 방문횟수 FROM 고객 WHERE 고객번호 = :cust_num for update; update 고객 set 적립포인트 = :적립포인트 where 고객번호 =: cust_num;select 시점에 Lock 을 거는 비관적 동시성 제어는 자칫 시스템 동시성을 심각하게 떨어뜨릴 우려가 있다. 그러므로 다음과 같이 wait 또는 nowait 옵션을 함께 사용하는 것이 바람직하다.
for update nowait -- 대기 없이 Exception 던짐 for update wait 3 -- 3초 대기 후 Exception 던짐SQL Server 에서도 for update 절을 사용할 수 있지만 커서를 명시적으로 선언할 때만 가능하다.
따라서 SQL Server 에서 비관적 동시성 제어를 구현할 때는 holdlock 이나 updlock 힌트를 사용하는 것이 편리하다.
낙관적 동시성 제어 Optimistic Concurrency Control
사용자들이 같은 데이터를 동시에 수정하지 않을 것이라고 가정하고 데이터를 읽을 때 Lock 을 설정하지 않는다.
대신 수정 시점에 다른 사용자에 의해 값이 변경됐는지를 반드시 검사해야한다.
SELECT 적립포인트, 방문횟수 FROM 고객 WHERE 고객번호 = :cust_num; UPDATE 고객 SET 적립포인트 = :적립포인트 WHERE 고객번호 = :cust_num AND 적립포인트 = :a AND 방문횟수 = :b; if sql%rowcount = 0 then alert('다른 사용자에 의해 변경되었습니다.'); end if최종 변경일시를 관리하는 칼럼이 있으면 더 간단하게 구현 가능하다.
SELECT 적립포인트, 방문횟수, 변경일시 INTO :a, :b, :mod_dt FROM 고객 WHERE 고객번호 = :cust_num; UPDATE 고객 SET 적립포인트 := 적립포인트, 변경일시 = SYSDATE WHERE 고객번호 = :cust_num AND 변경일시 = :mod_dt ;- Consistent 모드 읽기 쿼리 실행 시간에 상관없이 항상 쿼리가 시작된 시점의 데이터를 가져옴 ① CR copy 생성 없이 Current 블록을 읽어도 집계에 포함 ② SELECT 문에서 읽은 대부분의 블록 ③ CR 블록을 생성하려고 읽어들인 Undo 세크먼트 블록도 집계에 포함 - Consistent 모드에서 생길 수 있는 문제: ① TX2는 TX1에 걸린 Lock 대기 (Row Lock) ② t2 시점에 SAL은 1000이었므로 TX1이 commit된 후 1,000을 가지고 UDPATE (Read Committed라고 가정) ③ 최종값은 1200이 되고 TX1의 처리 결과는 사라짐, Lost Update 발생 - Current 모드 읽기 쿼리가 시작된 시점이 아닌 데이터를 찾아간 그 시점의 최종 값을 가져옴 ① DML문 수행 시 ② SELECT FOR UPDATE문 수행 시 ③ disk sort가 필요할 정도의 대량 데이터를 정렬 시 - Current 모드에서 생길 수 있는 문제: ① 인덱스(no)를 경유해 순차적으로 UPDATE를 진행하는 경우 → 50,001건이 UPDATE ② Full Table Scan 방식으로 UPDATE 진행하는 경우 → 레코드가 INSERT 되는 위치에 따라 UPDATE 결과 건수가 달라짐 (이미 지나간 블록에 삽입된다면 50,000 건 UPDATE, 앞으로 지나갈 블록에 삽입된다면 50,001 건 UPDATE) ※ UPDATE나 DELETE 에 대해서도 위와 같은 현상이 일어날 수 있다. Consistent 모드로 갱신대상을 식별하고, Current 모드로 갱신 - 실제 오라클이 UPDATE를 처리하는 방식 https://jungmina.com/786다중버전 동시성 제어
1. 일반적인 Locking 매커니즘의 문제점
동시성 제어의 목표는, 동시에 실행되는 트랜젝션의 수를 최대화하면서도 입력, 수정, 삭제, 검색 시 데이터 무결성을 유지하는 데 있다. 근데 읽기 작업에 공유 Lock 을 사용하는 일반적인 Locking 매커니즘에는 읽기과 쓰기가 서로 방해를 일으켜 종종 동시성에 문제를 생긴다.
또한 데이터 일관성에 문제가 생기는 경우가 있어 Lock 을 더 오래 유지하거나 테이블 레벨 Lock 을 사용해야하므고 동시성을 더 심각하게 떨어뜨린다.
TX1 > SELECT SUM(잔고) FROM 계좌; TX2 > UPDATE 계좌 SET 잔고 = 잔고+100 WHERE 계좌번호 = 7; TX2 > UPDATE 계좌 SET 잔고 = 잔고-100 WHERE 계좌번호 = 3; TX2 > COMMIT;TX1 이 2번 계좌까지 읽는다.
TX2 가 계좌 7 번에 UPDATE 를 실행한다.
TX1이 6번 계좌까지 읽는다.
TX2 가 계좌 3번에 UPDATE 를 실행한다.
TX1 이 10 번 계좌까지 읽는다 .
위 순서로 쿼리가 실행되면서 Read Commited 수준에서 잘못된 SUM 을 얻을 수 있고,
Repeatable Read 로 수준을 상향하면, 아래와 같은 교착상태가 발생한다.
TX2 가 계좌 7에 배타적 LOCK 을 설정한다.
TX1 이 계좌 3에 공유 LOCK 을 설정한다.
TX2 는 계좌 3에 걸린 공유 LOCK 을 대기한다.
TX1 은 계좌 7에 배타적 LOCK 을 대기한다.
2. 다중버전 동시성 제어 Multiversion Concurrency Control (MVCC)
읽기와 쓰기가 서로 방해해 동시성을 떨어뜨리고, 공유 Lock 을 사용함에도 일관성이 훼손될 수 있는 문제를 해결하기 위해 Oracle 은 버전 3부터 다중버전 동시성 제어(MVCC) 매커니즘을 사용해왔다.
다른 DBMS 들도 동시성과 일관성을 동시에 높이기 위해 MVCC 매커니즘을 제공하기 시작했다.
요약하면 다음과 같다.
- 데이터를 변경할 때마다 그 변경사항을 Undo 영역에 저장해둔다.
- 데이터를 읽다가 쿼리(또는 트랜젝션) 시작 시점 이후 변경된(변경 진행 중/이미 커밋된) 값을 발견하면, Undo 영역에 저장된 정보를 이용해 쿼리(또는 트랜젝션) 시작 시점의 일관성 있는 버전을(CR Copy) 생성하고 그것을 읽는다.
쿼리 도중에 배타적 Lock 이 걸린, 즉 변경이 진행 중인 레코드를 만나더라도 대기하지 않기 때문에 동시성 측면에서 매우 유리하다. 사용자에게 제공되는 데이터 기준 시점이 쿼리(또는 트랜젝션) 시작 시점으로 고정되기 때문에 일관성 측면에서도 유리하다.
장점도 있지만, Undo 블록 I/O, CR Copy 생성, CR 블록 캐싱 같은 부가적인 작업으로 오베헤드도 무시할 수 없다.
MVCC 를 이용한 읽기 일관성에는 문장수준과 트랜젠션 수준 2가지가 있다.
- 문장수준 읽기 일관성
다른 트랜젝션에 의해 데이터의 추가, 변경, 삭제가 발생하더라도 단일 SQL 문 내에서 일관성 있게 값을 읽는 것을 말한다.
alter database <데이터베이스 이름> set read_committed_snapshot on;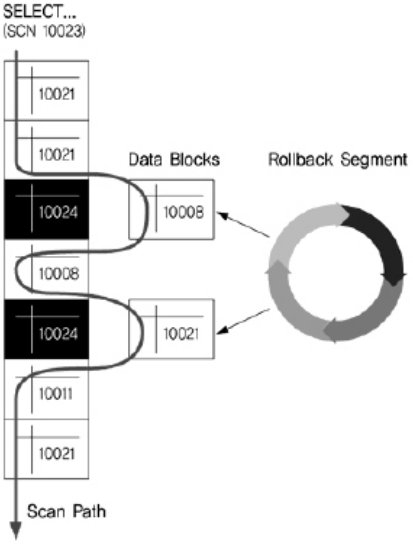
- 트랜젝션 수준 읽기 일관성
다른 트랜젝션에 의해 데이터의 추가, 변경, 삭제가 발생하더라도 트랜젝션 내에서 일관성 있게 값을 읽는 것을 말한다.
트랜젝션 내에 일관성을 보장받으려면 격리성 수준을 Serializable Read 로 올려야한다.
일관성 기준 시점은 트랜젝션 시작 시점이 되며, 트랜젝션이 진행되는 동안 자신이 발생시킨 변경사항은 그래도 읽는다.
alter database <데이터베이스 이름> set allow_snapshot_isolation on; set transation isolation level snapshot;- Snapshot too old
Undo 데이터를 활용해서 높은 수준의 동시성과 일관성을 유지하는 대신, 일반적인 Locking 매커니즘에 없는 Snapshot too old 에러가 MVCC 에서 발생한다. Undo 영역에 저장된 Undo 정보가 다른 트랜젝션에 의해 재사용돼 필요한 CR Copy 를 생성할 수 없을 때 발생한다.(좀 더 세부적인 매커니즘으로 들어가면 블록 클린아웃에 실패했을 때도 발생한다.)
이 에어 발생 가능성을 줄이는 방법은 다음과 같다.
1. Undo 영역의 크기를 증가시킨다.
2. 불필요하게 COMMIT 을 자주 수행하지 않는다.
3. fetch across commit 형태의 프로그램 작성을 피해 다른 방식으로 구현한다. ANSI 표준에 따르면 커밋 이전에 열려있던 커서는 더는 Fetch 하면 안된다. 다른 방식으로 구현이 어렵다면 commit 횟수를 줄여본다.
4. 트랜젝션이 몰리는 시간대에 오래 걸리는 쿼리가 같이 수행되지 않도록 시간을 조정한다.
5. 큰 테이블을 일정 범위로 나누고 단계적으로 실행할 수 있도록 코딩한다.
6. 오랜 시간에 걸쳐 같은 블록을 여러 번 방문하는 Nested Loop 형태의 조인문 또는 인덱스를 경유한 테이블 엑세스를 수반하는 프로그램이 있는지 체크하고, 이를 회피할 수 있는 방법(조인 메서드 변경, Full Table Scan 등)을 찾는다.
7. 소트 부하를 감수하더라고 order by 등을 강제로 삽입해 소트 연산이 발생하도록 한다.
8. 대량 업테이트 후 곧바로 해당 테이블 또는 인덱스를 full scan 하도록 쿼리를 수행하는 것도 하나의 해결 방법이 될 수 있다.
출처
SQL 전문가 가이드 - 한국데이터산업진흥원
반응형'데이터베이스' 카테고리의 다른 글
데이터베이스 아키텍처 (0) 2021.05.20 유저와 권한 (0) 2021.05.20 MERGE (0) 2021.05.20 정규 표현식 (POSIX /PERL) (0) 2021.05.17 PIVOT , UNPIVOT (0) 2021.05.16