-
1. 인라인 뷰 활용
대부분 조인 1:M 관계인 테이블끼리의 조인이다. 조인 결과는 M 쪽 집합과 같은 단위가 된다. 이를 다시 1쪽 집합 단위로 그루핑해야 한다면, M 쪽 집합을 먼저 1쪽 단위로 그루핑하고 나서 조인하는 것이 유리하다.
조인 횟수를 줄여주기 때문인데, 그런 처리를 위해 인라인 뷰를 사용할 수 있다.
2009년도 상품별 판매수량과 판매금액을 집계하는 아래 쿼리를 예로 살펴보자.
일별상품판매 t1 (M) : 상품 t2 (1)
select min(t2.상품명) 상품명, sum(t1.판매수량) 판매수량, sum(t1.판매금액) 판매금액 from 일별상품판매 t1, 상품 t2 where t1.판매일자 between '20090101' and '20091231' and t1.상품코드=t2.상품코드 group by t2.상품코드 ----------------------------------------------------------------------------- Rows Row Source Operation ----------------------------------------------------------------------------- 1000 SORT GROUP BY (cr=782160 pr=52744 pw=0 time=13804391 us) 365000 NESTED LOOPS (cr=782160 pr=52744 pw=0 time=2734163731004 us) 365000 TABLE ACCESS FULL 일별상품판매 (cr=52158 pr=51800 pw=0 time=456175026878 us) 365000 TABLE ACCESS BY INDEX ROWID 상품 (cr=730002 pr=944 pw=0 time=872397482545 us) 365000 INDEX UNIQUE SCAN 상품_PK (cr=365002 pr=4 pw=0 time=416615350685 us)Row Source Operation 을 분석해보면, 일별상품판매 테이블로부터 읽힌 365000개 레코드마다 상품 테이블과 조인을 시도했다. 조인 과정에서 730002 개의 블록 I/O 가 발생했고(cr 782160-52158), 총 소요시간은 13.8초이다.
다음과 같이 상품 코드별로 먼저 집계하고서 조인하도록 바꿔보자,
select t2.상품명, t1.판매수량, t1.판매금액 from ( select 상품코드, sum(판매수량) 판매수량, sum(판매금액) 판매금액 from 일별상품판매 where 판매일자 between '20090101' and '20091231' group by 상품코드 ) t1, 상품 t2 where t1.상품코드=t2.상품코드; ----------------------------------------------------------------------------- Rows Row Source Operation ----------------------------------------------------------------------------- 1000 SORT GROUP BY (cr=54259 pr=51339 pw=0 time=5540320 us) 1000 VIEW (cr=52158 pr=51339 pw=0 time=5531294 us) 1000 SORT GROUP BY (cr=52158 pr=51339 pw=0 time=5531293 us) 365000 TABLE ACCESS FULL 일별상품판매 (cr=52158 pr=51339 pw=0 time=2920041 us) 1000 TABLE ACCESS BY INDEX ROWID 상품 (cr=2101 pr=0 pw=0 time=8337 us) 1000 INDEX UNIQUE SCAN 상품_PK (cr=1101 pr=0 pw=0 time=3747 us)상품코드별로 먼저 집계한 결과 건수가 1000건이므로 삼품테이블과 조인도 1000번만 발생한다. 조인 과정에서 발생한 블록 I/O 는 2101개(cr 54259-52158)에 불과하고 수행시간도 5.5초밖에 걸리지 않았다.
* 조인 블록 I/O 수: cr 은 누적값이므로 조인에서 나온 cr 값에 그 전 cr 값을 뺀다.
2. 배타적 관계의 조인
어떤 엔티티가 두 개 이상의 다른 엔티티의 합집합과 관계를 갖는 것을 '상호 배타적' 관계라고 한다.
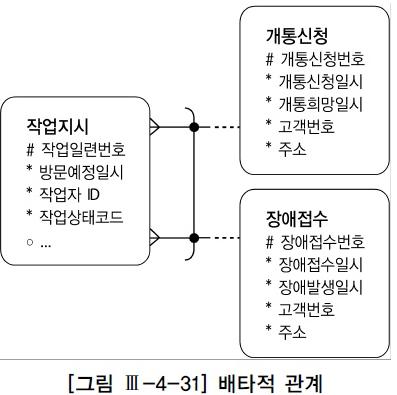
위와 같은 데이터 모델을 실제 데이터베이스로 구현할 때, 작업지시 테이블에는 아래 두 가지 방법 중 하나를 사용한다.
1. 개통신청번호와 장애접수번호 두 컬럼을 따로 두고, 레코드별로 둘 중 하나의 컬럼에만 값을 입력한다.
2. 작업구분과 접수번호 컬럼을 두고, 작업구분이 '1' 일 때는 개통신청번호를 입력하고 '2' 일 때는 장애접수번호를 입력한다.
1번처럼 설계할 때는 다음과 같이 Outer 조인으로 간단하게 쿼리를 작성할 수 있다.
select /*orderd use_nl(b) use_nl(c)/* a.작업일련번호, a.작업자ID, a.작업상태코드 ,nvl(b.고객번호,c.고객번호) 고객번호 ,nvl(b.주소,c.주소) 주소 from 작업지시 a, 개통신청 b, 장애접수 c where a.방문예정일시 between :방문예정일시1 and :방문예정일시2 and b.개통신청번호(+) = a.개통신청번호 and c.장애접수번호(+) = a.장애접수번호;2번처럼 설계했을 때는 약간의 고민이 필요하다. 가장 쉽게 생각할 수 있는 방법은 다음과 같이 Union All 을 이용하는 것이다.
select x.작업일련번호, x.작업자id, x.작업상태코드, y.고객번호, y.주소 from 작업지시 x, 개통신청 y where x.방문예정일시 between :방문예정일시1 and :방문예정일시2 and x.작업구분='1' and y.개통신청번호 = x.접수번호 union all select x.작업일련번호, x.작업자id, x.작업상태코드, y.고객번호, y.주소 from 작업지시 x, 장애접수 y where x.방문예정일시 between :방문예정일시1 and :방문예정일시2 and x.작업구분='2' and y.장애접수번호 = x.접수번호union all 을 중심으로 쿼리를 위아래 두 번 수행했지만,
만약 [작업구분+방문예정일시] 순으로 구성된 인덱스를 이용한다면 읽는 범위에 중복은 없다.
하지만 [방문예정일시+작업구분] 순으로 구성된 인덱스를 이용할 때는 인덱스 스캔 범위에 중복이 생긴다.
[방문예정일시] 만으로 구성된 인덱스를 이용하지만 작업구분을 필터링하기 위한 테이블 랜덤 액세스까지 중복해서 발생할 것이다.
그럴 때는 다음과 같이 쿼리함으로써 중복 액세스에 의한 비효율을 해소할 수 있다.
select /*+ordered use_nl(b) use_nl(c)*/ a.작업일련번호, a.작업자id, a.작업상태코드 ,nvl(b.고객번호, c.고객번호) 고객번호 ,nvl(b.주소, c.주소) 주소 from 작업지시 a, 개통신청 b, 장애접수 c where a.방문예정일시 between :방문예정일시1 and :방문예정일시2 and b.개통신청번호(+) = decode(a.작업구분,'1',a.접수번호) and c.장애접수번호(+) = decode(a.작업구분,'2',a.접수번호);3. 부등호 조인
일반적으로 '=' 연산자 조인에만 익숙하더라도 업무에 따라서는 between, like, 부등호 같은 연산자로 조인해야할 때도 있다.
예를 들어 아래 좌측과 같은 테이블이 있을때, 우측과 같은 형태의 누적매출을 구해보자.
지점별로 판매월과 함께 증가하는 누적매출을 구하는 것이다.
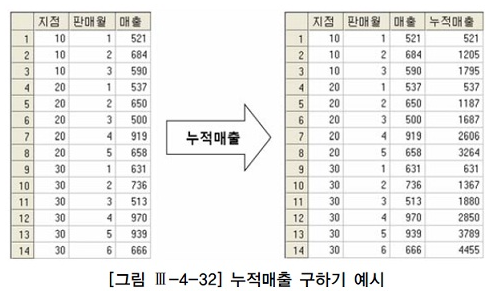
select 지점, 판매월, 매출, sum(매출) over (partition by 지점 order by 판매월 range between unbounded preceding and current row)매출 from 월별지점매출;만약 윈도우 함수가 지원되지 않는 DBMS 를 사용한다면 아래와 같이 부등호 조인을 이용해 같은 결과를 얻을 수 있다.
select t1.지점, t1.판매월, min(t1.매출) 매출, sum(t2.매출) 누적매출 from 월별지점매출 t1, 월별지점매출 t2 where t2.지점 = t1.지점 and t2.판매월 <= t1.판매월 group by t1.지점, t1.판매월 order by t1.지점, t1.판매월;4. BETWEEN 조인
가. 선분이력이란?
예를 들어 고객별연체금액 변경이력을 관리할 때 이력의 시작시점만 관리하는 것을 '점이력' 모델이라 하고,
시작시점과 종료시점을 함께 관리하는 것을 '선분이력' 모델이라고 한다.
선분이력 모델에서 가장 마지막 이력의 종료일자는 항상 '99991231' 로 입력해둬야한다.
이력을 이처럼 선분형태로 관리하면 무엇보다 쿼리가 간단해진다는 것이 가장 큰 장점이다.
예를 들어 123번 고객의 2004년 8월 15일 시점 이력을 조회하고자 할 때 다음과 같이 between 조인을 이용해 간편하게 조회할 수 있다.
select 고객번호, 연체금액, 연체개월수 from 고객별연체금액 where 고객번호='123' and '20040815' between b.시작일자 and b.종료일자;아래는 점이력으로 관리할 때의 쿼리이다.
select 고객번호, 연체금액, 연체개월수 from 고객별연체금액 a where 고객번호='123' and 연체변경일자 = (select max(연체변경일자) from 고객별연체금액 where 고객번호=a.고객번호 and 변경일자 <= '20040815');쿼리가 간단하면 아무래도 성능상 유리하지만, 이력이 추가될 때마다 기존 최종 이력의 종료일자도 같이 변경해줘야하는 불편함과 이 때문에 생기는 DML 부하를 고려해야한다.
PK 를 어떻게 구성하느냐에 따라 다르지만 성능을 고려해 일반적으로 [마스터 키+ 종료일자 + 시작일자] 순으로 구성하곤한다. 이럴 경우 이력을 변경할 때마다 PK 값을 변경하는 셈이어서 RDBMS 설계 사상에 맞지 않다는 지적을 받곤 한다. 무엇보다 개체 무결성을 완벽히 보장하기 어렵다는 것이 가장 큰 단점이다. 선분이력모델과 관련해 많은 이슈들이 존재한다.
나. 선분이력 기본 조회 패턴 -- 1개의 테이블에서 선분이력을 조회하는 경우
select 연체개월수, 연체금액 from 고객별연체금액 where 고객번호 = :cust_num and :dt between 시작일자 and 종료일자select 연체개월수, 연체금액 from 고객별연체금액 where 고객번호 = :cust_num and 종료일자 = '99991231'select 연체개월수, 연체금액 from 고객별연체금액 where 고객번호 = :cust_num and to_char(sysdate,'yyyymmdd') between 시작일자 and 종료일자다. 선분이력 조인 -- 2개 이상의 테이블에서 조인을 이용해 선분이력을 조인하는 경우
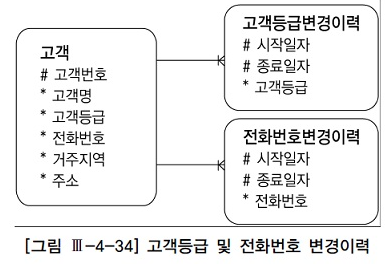
1) 과거/현재/미래의 임의 시점 조회
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호 from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2 where c.고객번호 =:cust_num and c1.고객번호=c.고객번호 and c2.고객번호=c.고객번호 and :dt between c1.시작일자 and c1.종료일자 and :dt between c2.시작일자 and c2.종료일자2) 현재 시점조회
만약 미래 시점 데이터를 미리 입력하는 예약 기능이 없다면 현재 시점 조회는 '=' 조건으로 만드는 것이 효과적이다.
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호 from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2 where c.고객번호 =:cust_num and c1.고객번호=c.고객번호 and c2.고객번호=c.고객번호 and c1.종료일자='99991231' and c2.종료일자='99991231'미래 시점 데이터를 입력하는 예약 기능이 있다면 , 현재 시점을 조회할 때 다음과 같이 한다.
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호 from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2 where c.고객번호 =:cust_num and c1.고객번호=c.고객번호 and c2.고객번호=c.고객번호 and to_char(sysdate,'yyyymmdd') between c1.시작일자 and c1.종료일자 and to_char(sysdate,'yyyymmdd') between c2.시작일자 and c2.종료일자라. Between 조인
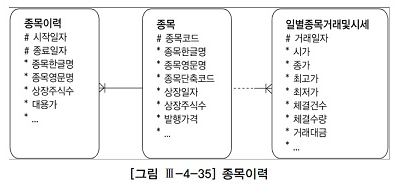
지금까지 선분이력 조건이 상수, 즉 조회 시점이 정해져있었다.
만약 위에 일별종목거래및시세 테이블과 같이 미지의 거래일자 시점으로 선분이력(종목이력)을 조회할 때는 between 조인을 이용하면 된다.
주식에서 과거 20년 동안 당일 최고가로 장을 마친(종가=최고가) 종목을 조회하는 쿼리이다.
일별종목거래및시세 테이블에서 시가/종가/거래 데이터를 읽어 그 당시 종목명과 상장주식수를 종목이력으로부터 가져온다.
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수 ,a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금 from 일별종목거래및시세 a, 종목이력 b where a.거래일자 between to_char(add_month(sysdate,-20*12),'yyyymmdd') and to_char(sysdate-1,'yyyymmdd') and a.종가 = a.최고가 and b.종목코드 = a.종목코드 and a.거래일자 between b.시작일자 and b.종료일자;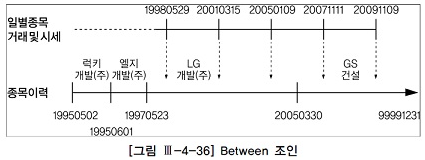
위 쿼리는 거래가 일어난 바로 그 시점의 종목명을 가져오는 것이 아니라 위 그림처럼 거래가 일어난 시점의 종목명을 읽는다. 현재 시점의 종목명을 가져오려면 between 조인이 아니라 다음과 같이 상수 조건으로 입력한다.
where a.거래일자 between to_char(add_month(sysdate,-20*12),'yyyymmdd') and to_char(sysdate-1,'yyyymmdd') and a.종가 = a.최고가 and b.종목코드 = a.종목코드 and to_char(sysdate,'yyyymmdd') between b.시작일자 and b.종료일자;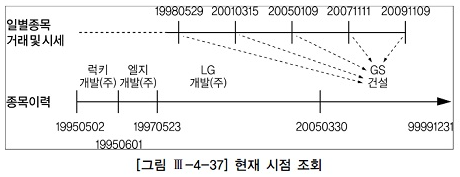
5. ROWID 활용
선분이력과 대비해, 데이터 변경이 발생할 때마다 변경일자와 함께 새로운 이력 레코드를 쌓는 방식을 '점이력' 이라고 흔히 말한다. 점이력 모델에선 서브 쿼리를 이용해 조회한다.
즉 찾고자 하는 시점보다 앞선 변경 일자 중 가장 마지막 레코드를 찾는 것이다.
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수 from 고객 a, 고객별연체이력 b where a.가입회사='C70' and b.고객번호=a.고객번호 and b.변경일자 = (select max(변경일자) from 고객별연체이력 where 고객번=a.고객번호 and 변경일자 <= a.서비스만료일) ----------------------------------------------- Execution Plan ----------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=845 Card=10 Bytes=600) 1 0 TABLE ACCESS (BY INDEX ROWID) OF '고객별연체이력' (Cost=2 Card=1 Bytes=19) 2 1 NESTED LOOPS (Cost=845 Card=10 Bytes=600) 3 2 TABLE ACCESS (BY INDEX ROWID)OF '고객' (Cost=825 Card=10 Bytes=410) 4 3 INDEX (RANGE SCAN) OF '고객_IDX01'(NON-UNIQUE) (Cost=25 Card=10) 5 2 INDEX (RANGE SCAN) OF '고객별연체이력_IDX01' (NON-UNIQUE) (Cost=1 Card=1) 6 5 SORT (AGGREGATE) (Cost=1 Bytes=13) 7 6 FIRST ROW (Cost=2 Card=5K Bytes=63K) 8 7 INDEX (RANGE SCAN (MIN/MAX)) OF '고객별연체이력_IDX01' (NON-UNIQUE)(..)SQL 과 실행계획에서 알 수 있듯이 고객별연체이력을 두 번 액세스하고 있다.
다행스럽게도 옵티마이저가 서브쿼리내에서 서비스만료일보다 작은 레코드를 모두 스캔하지 않고, 인덱스를 거꾸로 스캔하면서 가장 큰 값 하나만을 찾는 실행계획(7번째 라인 first row, 8번째 라인 min/max)을 수립했다.
만약 위 쿼리가 가장 빈번하게 수행되는 것이라서 단 한 블록 액세스라도 줄여야 한다면 ROWID 를 이용해 조인하는 튜닝 기법을 적용해 볼 수 있다.
select /*+ordered use_nl(b) rowid(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수 from 고객 a, 고객별연체이력 b where a.가입회사='C70' and b.rowid=( select /*+ index(c 고객별연체이력_idx01)*/ rowid from 고객별연체이력 c where c.고객번호 = a.고객번호 and c.변경일자 <= a.서비스만료일 and rownum <=1 ) ----------------------------------------------- Execution Plan ----------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=835 Card=100K Bytes=5M) 1 0 NESTED LOOPS (Cost=835 Card=100K Bytes=5M) 2 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (Cost=825 Card=10 Bytes=410) 3 2 INDEX (RANGE SCAN) OF '고객_IDX01'(NON-UNIQUE) (Cost=25 Card=10) 4 1 TABLE ACCESS (BY USER ROWID) OF '고객별연체이력' (Cost=1 Card=10K Bytes=137K) 5 4 COUNT (STOPKEY) 6 5 INDEX (RANGE SCAN) OF '고객별연체이력_IDX01' (NON-UNIQUE)(..)고객(a) 에서 읽은 고객번호로 서브쿼리 고객연체이력 c와 조인하고, 거기서 얻은 rowid 로 고객별 연체이력 b를 바로 액세스한다. a와 b간에 따로 조인문을 기술하는 것은 불필요하다.
쿼리에서 고객별연체이력을 두 번 참조했지만, 실제 계획 상에는 한 번만 조인한 것과 일량이 같다.
일반적인 NL 조인과 같은 프로세스(Outer인덱스>Outer 테이블>Inner 인덱스>Inner 테이블) 로 진행된다.
위 쿼리가 제대로 작동하려면 고객별연체이력_idx01 인덱스가 반드시 [고객번호+변경일자]순으로 구성돼있어야한다.
혹시라도 인덱스 구성이 변경되면 쿼리 결과가 달라질 수 있다!
first row(min/max) 알고리즘이 작동한다면 일반적으로 그것만으로 충분한 성능을 내 위와 같은 기법을 적용하지 않는 것이 좋다. 그럼에도 성능이 아주 중요한 프로그램이라 위 방식을 쓰게 된다면 이들 프로그램 목록을 관리했다가 인덱스 구성 변경 시 확인하는 프로세스를 반드시 거쳐야한다.
SQL 서버는 오라클처럼 사용자가 rowid 를 이용해 테이블을 액세스하는 방식(Table Aceess by User Rowid)을 지원하지 않는다.
출처
SQL 전문가 가이드 - 한국데이터산업진흥원
반응형