-
그룹함수의 종류
AGGREGATE FUNCTION COUNT,SUM,AVG,MAX,MIN 등 각종 집계 함수
2021.05.05 - [데이터베이스] - SQL 기본과 활용 (단일함수, 집계함수)GROUP FUNCTION ROLLUP : 집계함수를 제외, 소그룹 간 소계를 계산
CUBE : GROUP BY 항목 간 다차원적인 소계를 계산
GROUPING SET : 특정 항목에 대한 소계를 계산WINDOW FUNCTION RANK
DENSE_RANK
ROW_NUMBER
SUM,MAX,MIN,COUNT
FIRST_VALUE
LAST_VALUE
LAG
LEAD
RATIO_TO_REPORT
PERCENT_RANK
CUME_DIST
NTILE
2021.05.15 - [데이터베이스] - 윈도우 함수GROUP FUNCTION
예) 직원 테이블과 부서테이블에서 부서이름, 직업별로 직원 수와 임금 합계를 출력한다.
1. GROUP BY 절 사용
SELECT B.DNAME ,A.JOB ,COUNT(*) AS EMP_CNT ,SUM(A.SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO=A.DEPTNO GROUP BY B.DNAME,A.JOB ORDER BY B.DNAME,A.JOB;2. ROLLUP 함수 사용
명시한 표현식 수와 순서(오른쪽에서 왼쪽 순으로)에 따라 레벨별로 집계한 결과가 반환된다.
표현식 개수가 N개이면 N+1 레벨까지, 하위 레벨에서 상위 레벨 순으로 데이터가 집계된다.
SELECT B.DNAME ,A.JOB ,COUNT(*) AS EMP_CNT ,SUM(A.SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO=A.DEPTNO GROUP BY ROLLUP(B.DNAME,A.JOB) ORDER BY B.DNAME,A.JOB;1번은 GROUP BY 는 ( 부서 - 직업 - 인원수 - 임금합계 ) 로 집계된 정보들을 출력하는데 ,
2번은 ROLLUP 은 위 정보에 부서별로 ( 부서 - 부서 내 총 인원수 - 부서 내 임금 총합계 ) 로 소집계된 ROW 가 한 줄씩 더 추가되고, 마지막에 모든 부서의 (총 인원수 - 총 임금합계) 가 추가로 나온다.
부서(GROUPING COLUMNS)가 N 개라면 N+1 개만큼의 SUB TOTAL 이 생성된다.
ROLLUP 의 인수는 계층구조라 인수의 순서가 바뀌면 수행 결과도 바뀌므로 순서에도 주의해야한다.
ROLLUP 의 인수로 DNAME , JOB 2개의 인수가 (N+1) 3단계 레벨을 생성한다.
3차 레벨은 DNAME, JOB 이 함께 있고,
2차 레벨은 JOB 의 소계이다. (오른쪽에서 왼쪽)
1차 레벨은 마지막에 DNAME, JOB 의 총계를 보여준다.

만약 GROUP BY ROLLUP(DNAME), JOB 과 같이 ROLLUP 대상을 하나로 잡으면
(DNAME,JOB) 이 2레벨, JOB 이 1레벨이 되고, DNAME 이 소계된다.
또 ROLLUP 을 다른 유형으로 사용할 수 있는데,
GROUP BY expr1, ROLLUP(expr2, expr3)로 명시했다면,
레벨은 ‘2+1=3’ 레벨이 되지만 결과는 (expr1, expr2, expr3), (expr1, expr2), (expr1) 별로 집계가 되고
전체 합계는 집계되지 않는다. 이런 유형을 분할(partial) ROLLUP이라고 한다.
GROUPING 함수 사용
ROLLUP,CUBE,GROUPING SETS 를 새로운 그룹 함수를 지원하기 위해 GROUPING 함수가 추가됐다.
ROLLUP 이나 CUBE 에 의한 소계가 계산된 결과에는 GROUPING(expr)=1 이 표시되고,
그 외 결과는 GROUPING(expr)=0 이 표시 된다.
아래 쿼리에서 DNAME_GRP , JOB_GRP 가 있는데
JOB_GRP 에 1 이 나오는 의미는 모든 JOB 을 더한, JOB 의 소계 값이라는 의미이다.
마지막 줄에 JOB_GRP 와 DNAME_GRP 둘 다 1이 나왔는데 이는 총계라는 의미이다.
GROUPING 값 으로 소계와 총계를 구분할 수 있다.
SELECT B.DNAME , GROUPING (B.DNAME) AS DNAME_GRP ,A.JOB , GROUPING(A.JOB) AS JOB_GRP ,COUNT(*) AS EMP_CNT ,SUM(A.SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO=A.DEPTNO GROUP BY ROLLUP(B.DNAME,A.JOB) ORDER BY B.DNAME,A.JOB;
GROUPING 함수 WITH CASE 함수
SELECT CASE GROUPING (B.DNAME) WHEN 1 THEN 'All depts' ELSE B.DNAME END AS DNAME ,GROUPING(A.JOB) WHEN 1 THEN 'All jobs' ELSE A.JOB END AS JOB ,COUNT(*) AS EMP_CNT ,SUM(A.SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO=A.DEPTNO GROUP BY ROLLUP(B.DNAME,A.JOB) ORDER BY B.DNAME,A.JOB;
만약 ROLLUP 함수를 JOBS 에만 적용하게 되면 위 사진에서 ALL department 가 표시된 마지막 줄을 빼고 동일하게 나온다.
CUBE
ROLLUP 에서는 단지 가능한 SUBTOTAL 만 생성하지만,
CUBE 에서는 결합 가능한 모든 값에 대해 다차원 집계를 생성한다.
CUBE 를 사용할 때 내부적으로 GROUPING COLUMNS 의 내부 순서를 바꿔 또 한 번 쿼리를 추가 수행한다.
그리고 Grand Total 은 양쪽 쿼리에서 모두 생성돼, 한번의 쿼리에서는 제거해야하므로 ROLLUP 에 비해 연산이 많다.
CUBE 함수의 경우 표시된 인수들에 대한 계층별 집계를 구할 수 있으며, 이때 표시된 인수 간에는 계층 구조인 ROLLUP 과는 달리 평등한 관계이므로 인수의 순서가 바뀌어도 행간 순서만 바꾸고 데이터 결과는 동일하다.
아래와 같이 부서와 직업별로 매칭된 데이터가 추가된다. GROUPING COLUMNS 이 N 개면 2의 N승만큼 나온다.

CUBE 함수가 없다면 부서와 직업별 데이터 , 전체 부서, 전체 직업, 전체부서와 전체 직업을 선택하는 SELECT 절을 만들어 UNION ALL 을 해야해야하니, 결과적으로 수행 속도 및 자원 사용률을 개선할 수 있고 가독성도 높일 수 있다.
CUBE 함수 미사용 예시 )
SELECT DNAME, JOB, COUNT(*) AS EMP_CNT, SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO = A.DEPTNO GROUP BY DNAME, JOB UNION ALL SELECT DNAME, 'All Jobs' AS JOB, COUNT(*) AS EMP_CNT, SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO = A.DEPTNO GROUP BY DNAME UNION ALL SELECT 'All Departments' AS DNAME, JOB, COUNT(*) AS EMP_CNT, SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO = A.DEPTNO GROUP BY JOB UNION ALL SELECT 'All Departments' AS DNAME, 'All Jobs' AS JOB, COUNT(*) AS EMP_CNT, SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO = A.DEPTNO;GROUPING SETS
아래와 같이 부서별 모든 직업, 직업별 모든 부서 정보를 원한다면 GROUPING SET 을 이용해서 쿼리를 간단하게 할 수 있다.
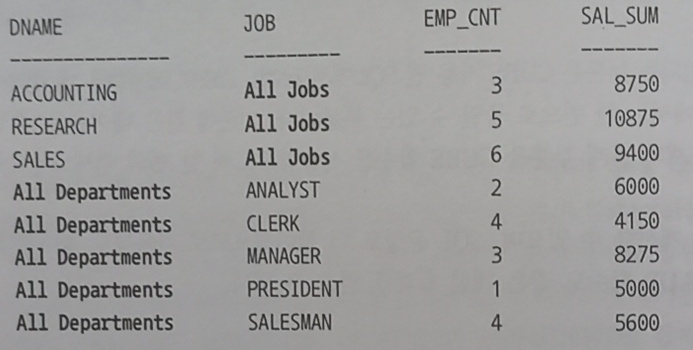
1. 일반함수 사용
SELECT DNAME ,'All Jobs' AS JOB ,COUNT(*) AS EMP_CNT ,SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO = A.DEPTNO GROUP BY DNAME UNION ALL SELECT 'All Departments' AS DNAME ,JOB ,COUNT(*) AS EMP_CNT ,SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B GROUP BY JOB;2. GROUPING SETS 사용
SELECT CASE GROUPING (B.DNAME) WHEN 1 THEN 'All Departments' ELSE B.DNAME END AS DNAME ,CASE GROUPING (A.JOB) WHEN 1 THEN 'All Jobs' ELSE A.JOB END AS JOB ,COUNT(*) AS EMP_CNT ,SUM(SAL) AS SAL_SUM FROM EMP A, DEPT B WHERE B.DEPTNO = A.DEPTNO GROUP BY GROUPING SETS (B.DNAME,A.JOB) ORDER BY B.DNAME,A.JOB;
출처
SQL 전문가 가이드 - 한국데이터산업진흥원
반응형